
Co je crawlování ve vyhledávání?
Crawlování je proces, při kterém roboti vyhledávacích nástrojů (web crawler, pavouci) objevují, procházejí a stahují obsah na různých URL adresách. Neprocházejí ale všechny URL adresy. Některé můžete vyjmout pomocí informace v souboru robots.txt.
Crawler o stránce shromažďuje údaje včetně textu, obrázků či videí a snaží se co nejlépe pochopit její obsah. Získaná data uloží do indexu – virtuální databáze, ze které pocházejí všechny výsledky vyhledávání.
Proč potřebujete, aby byl web crawlován?
Bez crawlování a následné indexace se web neobjeví ve výsledcích vyhledávání. To znamená, že se nezobrazíte v Googlu a potenciální zákazníci najdou po zadání poptávky jen konkurenční stránky.
Problémy s crawlováním a indexací se nemusí týkat celé stránky. Někdy chybí důležitá podstránka nebo Google indexuje nový obsah příliš pomalu.
Pro zpravodajské weby je pomalá indexace stejně velký problém jako žádná. Pokud píšete o výsledcích sportovních utkání nebo aktuálních událostech, které se do indexu dostávají s časovým zpožděním, máte problém.
Jak funguje crawlování webových stránek?
Práce crawlerů je přesně definovaná a sestává se z následujících kroků:
- Objevování URL adres: Existuje několik způsobů, jak se crawleři dozví o nových stránkách. Pomocí sitemap, přes dříve prohledávané weby nebo interní a externí odkazy.
- Stažení obsahu: Když crawler objeví URL adresu, stáhne její obsah včetně HTML, obrázků a jiných mediálních souborů.
- Indexování a extrahování odkazů: Stažený obsah crawler analyzuje a rozhodne o jeho zařazení, nebo nezařazení do indexu. Zaindexované URL adrese přidělí pro konkrétní klíčová slova pozici ve výsledcích vyhledávání. Zároveň vytáhne odkazy do dalšího plánu crawlování. Samozřejmě jen ty, které jsou podstatné a odpovídají pokynům webu.
- Prioritizace URL adres: Každou URL adresu, kterou potřebuje crawler opět navštívit, zařadí do seznamu a přiřadí její prioritu na základě relevance a důležitosti.
Proč nejsou všechny stránky zaindexované?
Crawlováním webových stránek vyhledávač, nejčastěji Google, neustále doplňuje index o nové stránky. Takto nonstop aktualizuje data o nový obsah.
Google pochopitelně neindexuje všechny stránky. Mnohé ani nepotřebujete, aby zaindexoval (například některé podstránky vytvořené filtrací, vybrané varianty produktů nebo kroky v košíku).
Nedochází k indexaci
Chybějící indexace stránky často souvisí se zákazem procházení dané podstránky uvedeným v souboru robots.txt. Nastavuje se pomocí příkazu „disallow“. Pokud máte v robots.txt podstránky za příkazem disallow, prověřte, zda opravdu chcete, aby roboti stránky nenavštěvovaly, nebo jde o omyl.
Zajímá vás, v jakém stavu je váš web? Vygenerujte si PDF audit webu.
Jak optimalizovat crawlování webových stránek?
Pro zvýšení efektivity procházení webové stránky potřebujete jednoduchou strukturu URL adres, srozumitelné sitemapy, síť interního a externího prolinkování a několik dalších nástrojů a taktik. Všechny si postupně projdeme také s praktickými ukázkami.
Optimalizujte XML sitemapy
Pro organizaci webu pro boty slouží sitemapa, která má xml formát a doporučujeme ji pro každý web, který má více než 100 podstránek. V ideálním případě ji generujte pomocí pluginů pravidelně a automaticky.
Jak vypadá a co obsahuje sitemapa?
Na první pohled vypadá jako obsah webu, ale pro roboty. Díky ní vědí, které stránky webu jsou ty nejdůležitější. V sitemapách by měly být pouze ty stránky, které chcete, aby skončily v indexu.
Sitemapa by měla kromě URL adresy obsahovat také datum poslední modifikace. Díky němu přicházející robot ví, na kterých stránkách od jeho poslední návštěvy nastaly změny.
Pozor na crawl budget a průchodnost webu
Každý web potřebuje, aby roboti od Google pravidelně navštěvovaly důležité podstránky a co nejdříve odhalily nové. Robot má však na web vyhrazenou jen omezenou výpočetní kapacitu. Jak z ní vytěžit co nejvíc?
Co je to crawl budget
Vyhledávač přiděluje webovým stránkám crawl budget na základě odezvy ze serveru, velikosti webu, frekvence, kterou aktualizujete stránky a prolinkování stránek (interního i externího). Zjednodušeně můžeme říci, že Google prochází populární URL adresy mnohem častěji.
„Nejzásadnější nástroj pro optimalizaci crawlování je rozhodně dobře nakonfigurovaný robots.txt a pravidelně aktualizovaná Sitemapa s dobře nastaveným <lastmod> tagem.
Jako SEO specialisté však musíme monitorovat a zajistit „zdraví procházení“. To znamená eliminovat 5XX stavové kódy, soft 404 či řetězové přesměrování. Nesmíme zapomenout ani na každodenní chlebíček SEO specialisty, duplicitní obsah,“ prozrazuje náš SEO specialista Martin Gajdoš.
Odstraňte duplicitní stránky z vyhledávání
Duplicitní obsah komplikuje indexování webu. Duplicita znamená, že existuje více URL adres, na kterých je identický nebo velmi podobný obsah. Googlebot se pak nedokáže rozhodnout, která stránka je hlavní, a může mylně přidělit nesprávnou hodnotu. Výsledkem jsou nižší pozice ve vyhledávání.
V případě e-shopuE-shop nebo jinými slovy internetový obchod je virtuální platforma, na které nakupujete nebo prodáváte produkty přes internet. Díky neomezen... More vzniká duplicita nejčastěji filtrací produktů. Stává se to zejména u ceny. Pokud návštěvník posune cenu, byť jen o jedno euro, pravděpodobně se zobrazí velmi podobná stránka s téměř identickým obsahem a duplicita je na světě.
V takovém případě musíte URL adresu odlišit při každé jedné filtraci, správně nastavit kanonizaci nebo zakázat botům procházení těchto stránek v robots.txt.
Příklad z praxe: IBO
U partnera IBO jsme museli vyřešit především problém s technickým SEO. Komplikace vznikaly při indexaci, kdy roboti procházely také stránky bez větší hodnoty.
E-shop měl více než 3 miliony indexovaných stránek a 6 milionů neindexovaných, z nichž většinu tvořily duplicity z filtrace.
Problém jsme vyřešili správným nastavením pravidel indexace pro vyhledávače.
U web stránky takových rozměrů vždy řešte crawl budget (výpočetní kapacitu, kterou vyhledávač alokuje na zpracování stránky) a jeho efektivní využití.
Nakonfigurovali jsme soubor robots.txt, který jasně stanoví pravidla pro roboty. Vytvořili jsme také samostatné sitemapy pro kategorie produktů, jednotlivé produkty nebo vyprodaný sortiment. Vyloučili jsme z indexování všechny podstránky, které vznikají při vyhledávání na webu, při registraci nebo přihlášení se do účtu.
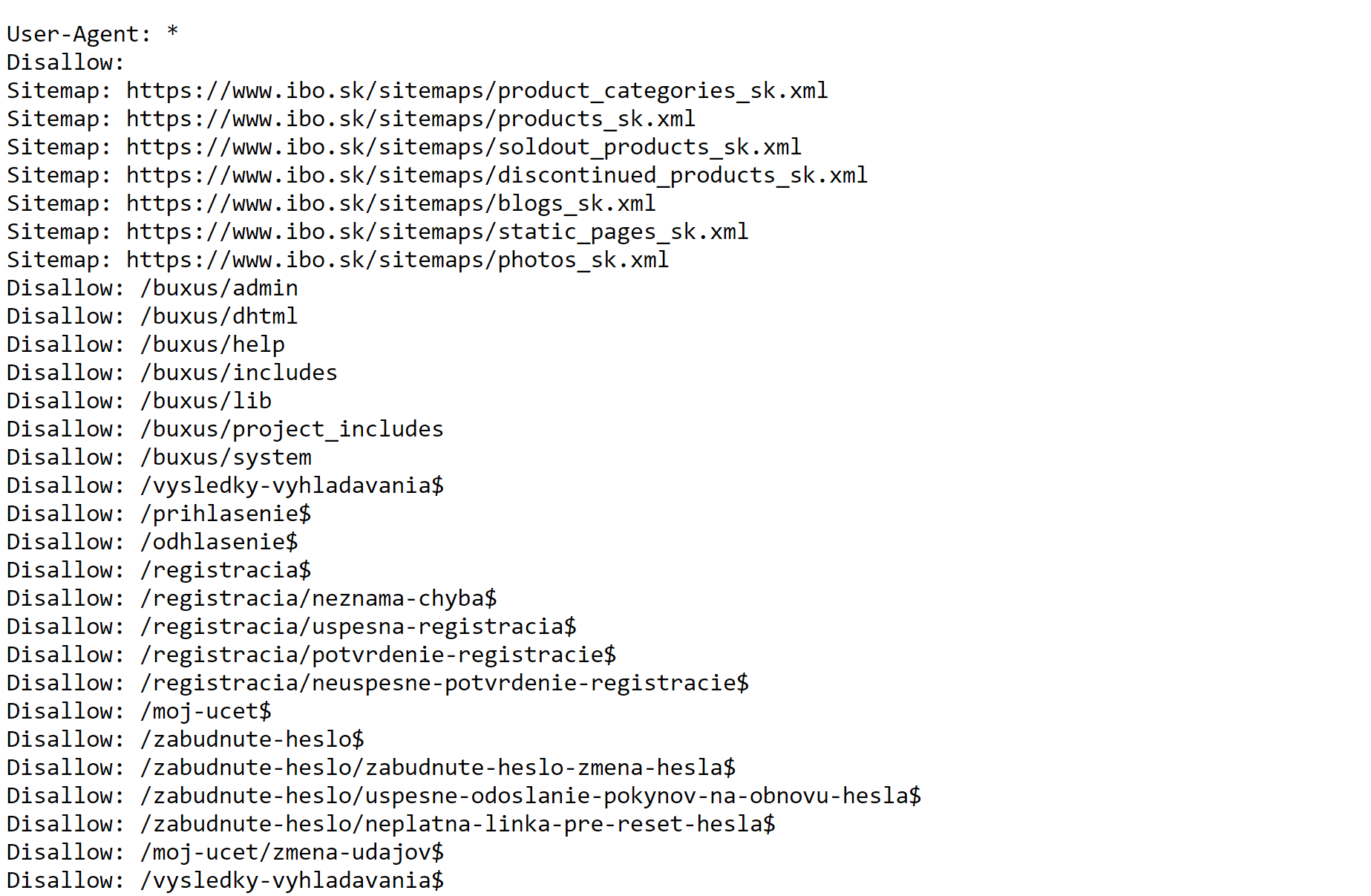
Robots.txt pro web ibo.sk, kde jsme upravili pravidla indexace pro Googleboty s ohledem na cíle e-shopu.
Spolu s úpravou textů v hlavních kategoriích, tvorbou blogu, interním prolinkováním a kvalitním obsahem se nám podařilo dostat IBO na průměrnou první pozici na všechny relevantní fráze. Meziročně vzrostl počet impresí o 133 % a organická návštěvnostCo si představit pod pojmem organická návštěvnost? Organická návštěvnost je důležitým pilířem digitálního marketingu. Představuje ná... More o 26 %.
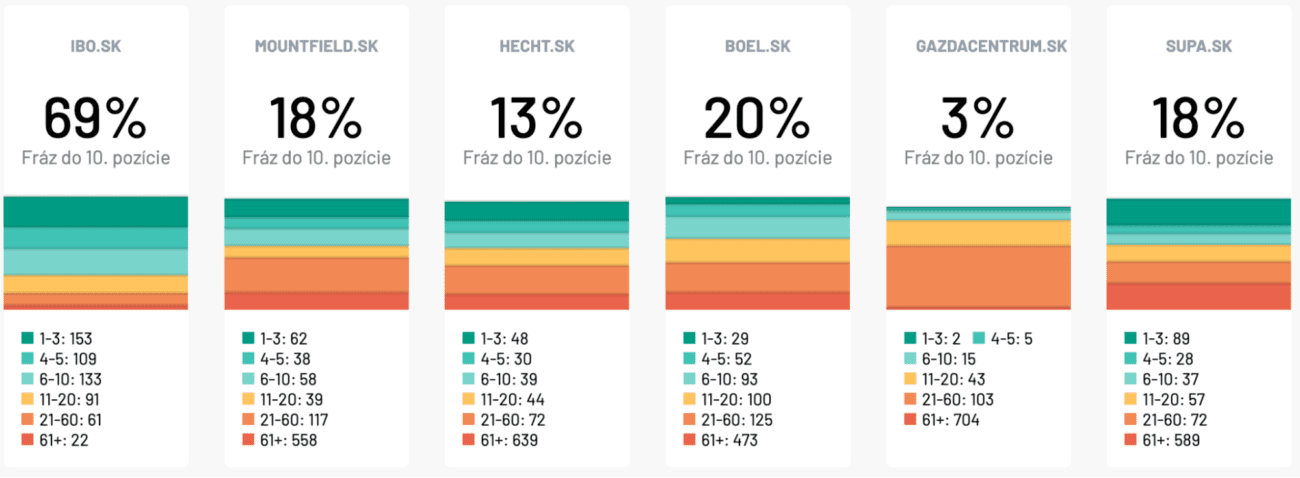
Až 69 % sledovaných klíčových slov se zobrazuje na Google do maximálně desáté pozice. Představuje to několikanásobný náskok před konkurencí.
Podpořte crawlování interními odkazy
Interní odkazy mají velký vliv na efektivní crawlování. Optimalizujte strukturu interních odkazů na webové stránce a zajistěte snadnou navigaci a přístupnost relevantních stránek.
Pokud strategicky propojíte různé webové stránky, dáte crawlerům jednoznačně najevo, že stránka A souvisí se stránkou B. Zároveň tak vyhledávač lépe pochopí obsah webu a vzájemné propojení stránek.
Skvělou technikou pro budování interního prolinkování jsou tematické klastry.
Odstraňte obsah bez hodnoty
Vyčistěte webovou stránku od nekvalitního, zastaralého nebo duplicitního obsahu, který odvádí pozornost crawlerů od nového nebo nedávno aktualizovaného obsahu. Slučte podobný obsah a použijte přesměrování 301.
Neindexuje se váš web správně?
Crawlování webových stránek je klíčovým aspektem SEO a ovlivňuje indexování vašeho obsahu ve výsledcích vyhledávání. Pokud se váš obsah indexuje pozdě, máte problém s duplicitními podstránkami nebo crawl budgetem, rádi vám pomůžeme.
Náš tým SEO specialistů má zkušenosti s malými i velkými e-shopy a zajistí, aby Google našel a správně zaindexoval všechny nejdůležitější podstránky.



